$1 for 7 million tokens, powerful MoE model is open sourced, its performance is close to GPT-4-Turbo.
In the field of open source large models, another strong competitor has emerged.
Recently, DeepSeek AI, a company exploring the nature of Artificial General Intelligence (AGI), has open-sourced a powerful Mixture of Experts (MoE) language model, DeepSeek-V2, which boasts lower training costs and more efficient inference.

- Project address: https://github.com/deepseek-ai/DeepSeek-V2
- Paper title: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-V2 has 236B parameters, with each token activating 21B parameters, and supports a context length of 128K tokens.
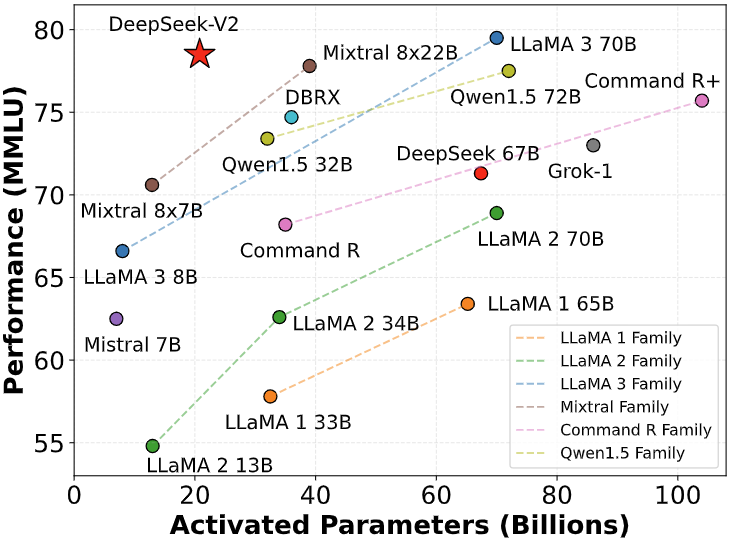
Compared to DeepSeek 67B (which was launched last year), DeepSeek-V2 has achieved stronger performance, saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput by 5.76 times.
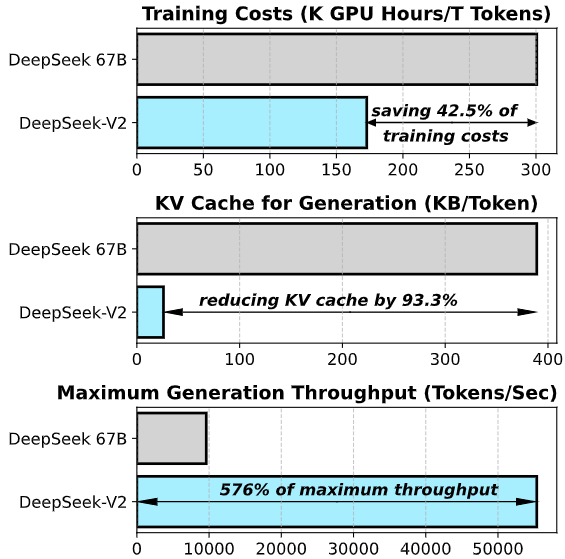
The performance of DeepSeek-V2 is very impressive: it surpasses GPT-4 on the AlignBench benchmark and is close to GPT-4-turbo; it is comparable to LLaMA3-70B in MT-Bench, and better than Mixtral 8x22B; it excels in mathematics, coding, and reasoning.
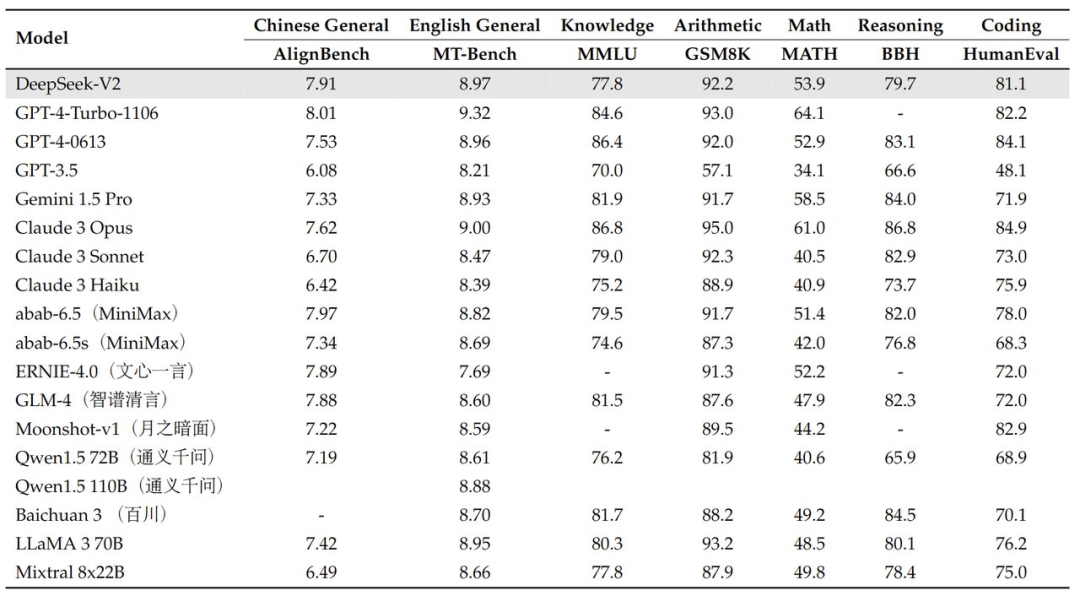
Here are the comparison results of DeepSeek-V2 with LLaMA 3 70B, Mixtral 8x22B, and DeepSeek V1 (Dense-67B):
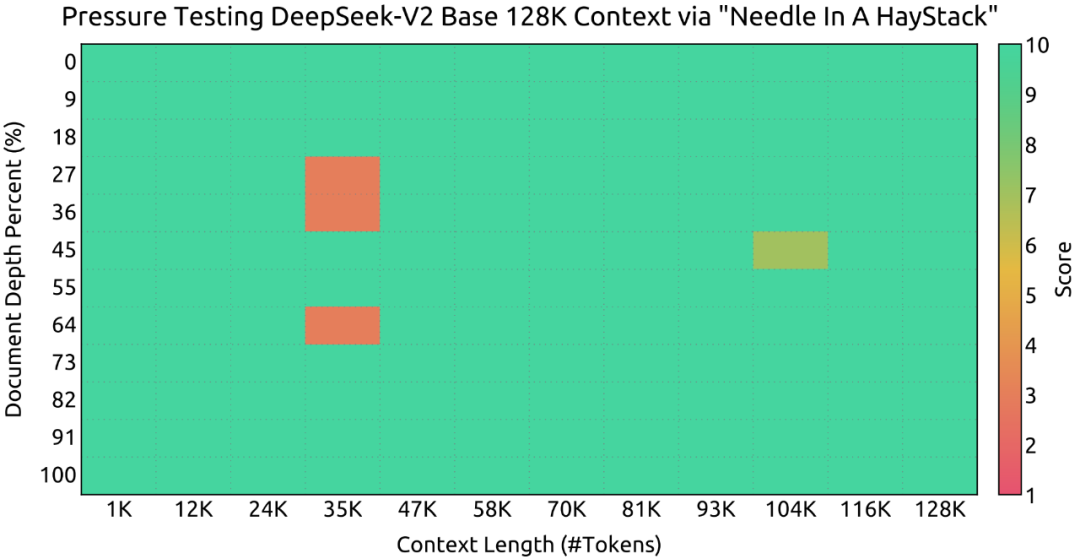
In the NEEDLE IN A HAYSTACK task, DeepSeek-V2 performs well when the context window reaches 128K.
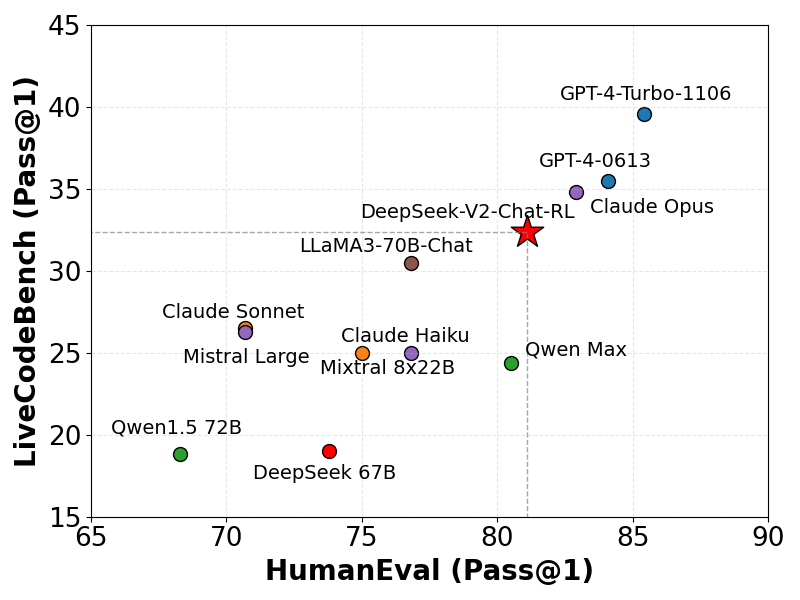
On LiveCodeBench (0901-0401 ‘a benchmark designed specifically for real-time coding challenges’), DeepSeek-V2 has achieved a higher Pass@1 score.
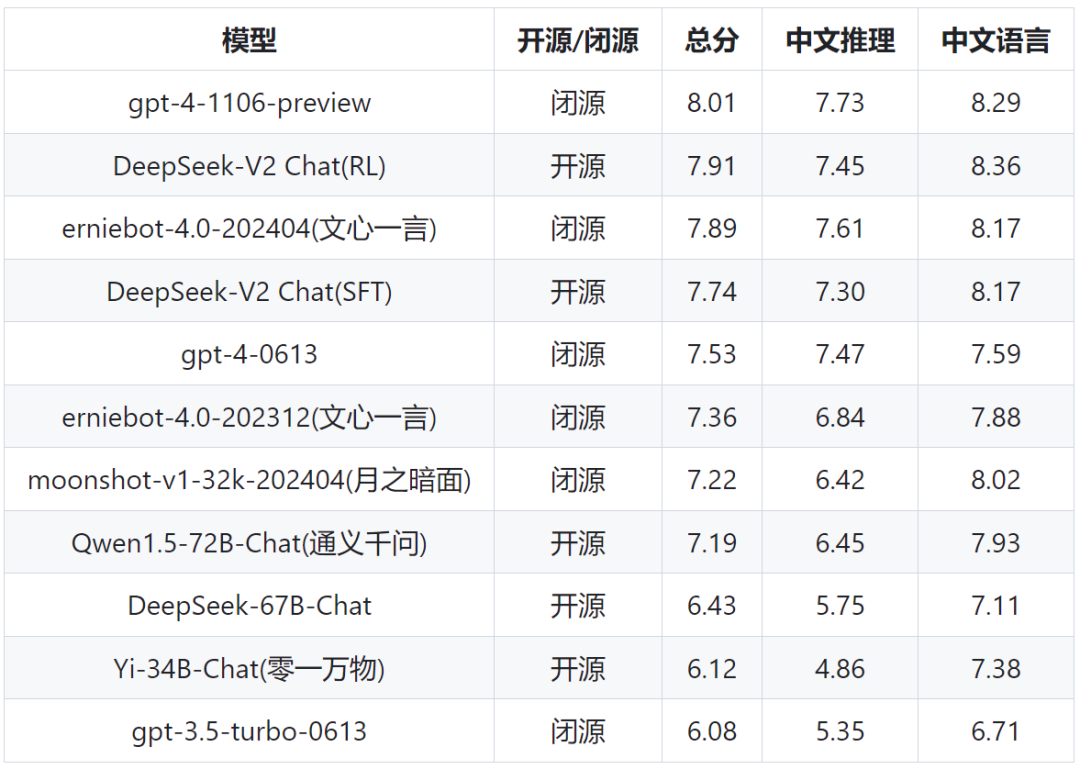
Performance of DeepSeek-V2 compared with different models in Chinese reasoning and Chinese language:
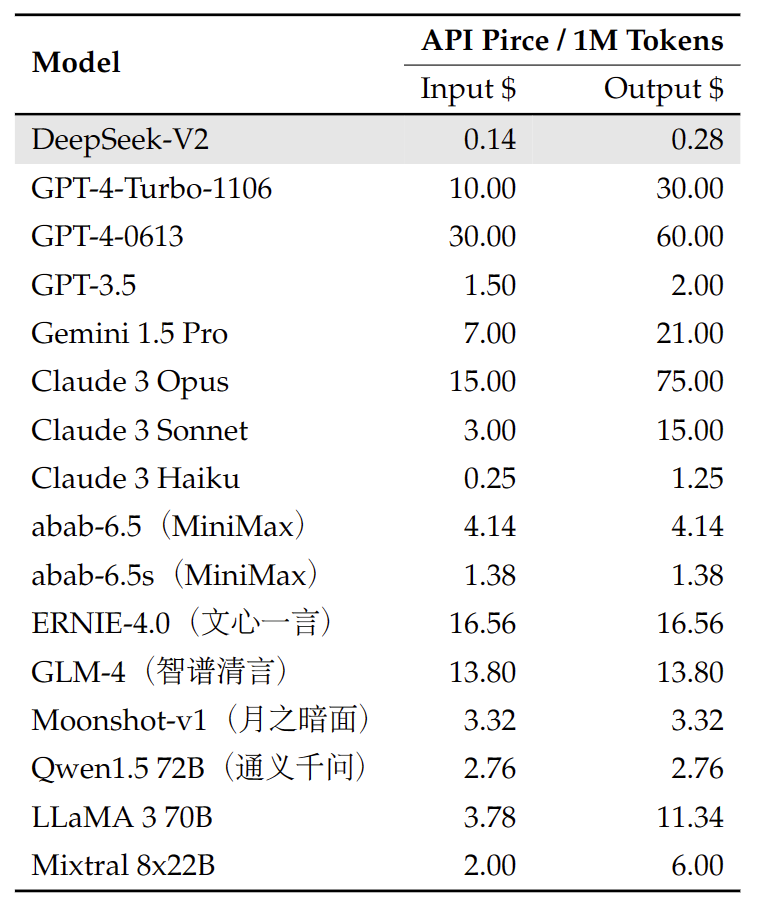
In terms of pricing, the pricing of the DeepSeek-V2 API is as follows: $0.14 per million token input (about 1 yuan RMB), $0.28 for output (about 2 yuan RMB, 32K context). Compared with the pricing of GPT-4-Turbo, the price is only nearly one percent of the latter.
Model Introduction
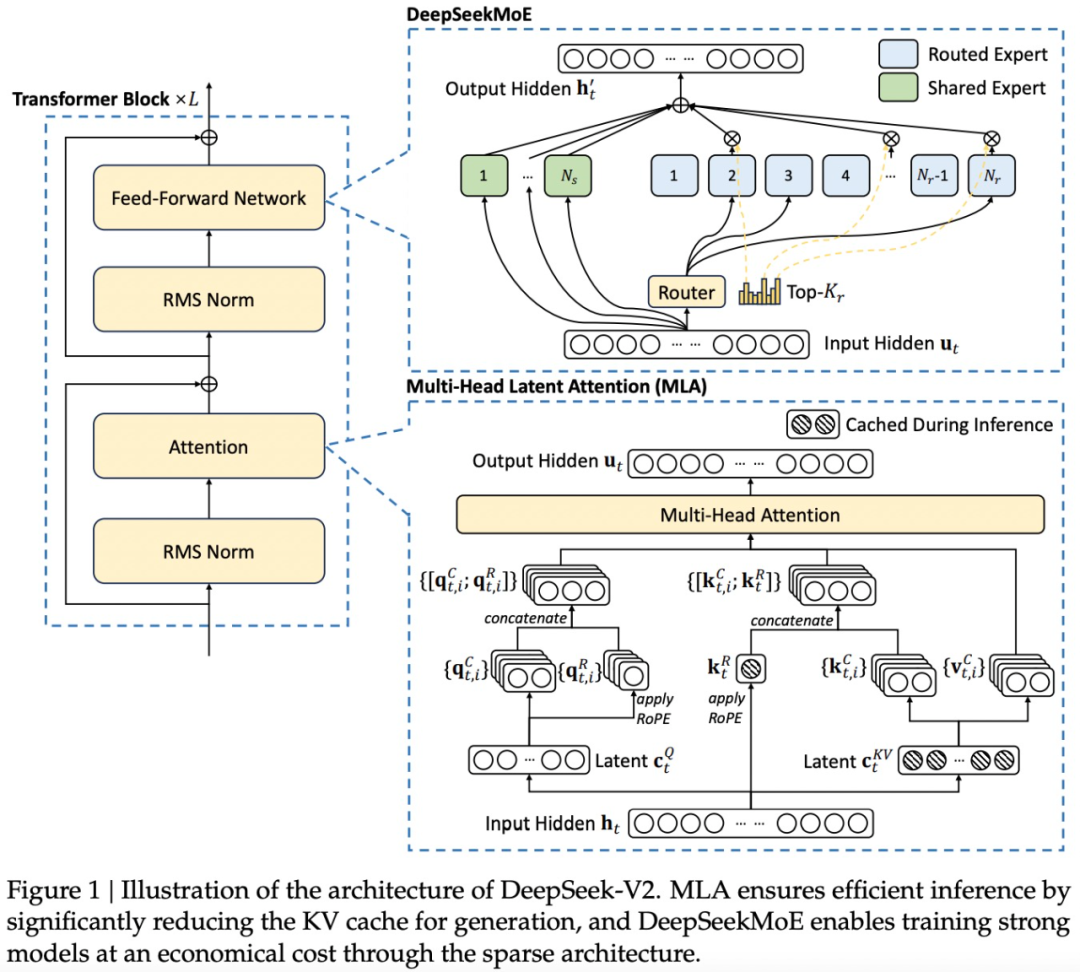
DeepSeek-V2 uses the Transformer architecture, where each Transformer block comprises an attention module and a feed-forward network (FFN). However, for the attention module and FFN, the research team has designed and adopted innovative architectures.
On the one hand, the research has designed MLA, which uses low-rank key-value joint compression to eliminate the bottleneck of key-value caching during inference, thus supporting efficient inference.
On the other hand, for the FFN, the research adopts the high-performance MoE (Mixture of Experts) architecture — DeepSeekMoE, to train powerful models economically.
In some details, DeepSeek-V2 follows the DeepSeek 67B setup. The architecture of DeepSeek-V2 is as shown in the following diagram:
The research team has built a high-quality, multi-source pre-training corpus composed of 8.1T tokens. Compared with the corpus used by DeepSeek 67B, this corpus has a larger data volume, especially Chinese data, and higher data quality.
The research first pre-trained DeepSeek-V2 on the complete pre-training corpus, and then collected 1.5 million dialogues covering various domains such as mathematics, code, writing, reasoning, and security, in order to execute supervised fine-tuning (SFT) for DeepSeek-V2 Chat. Finally, following the approach of DeepSeekMath, the research uses Group Relative Policy Optimization (GRPO) to further align the model with human preferences.
DeepSeek-V2 was trained on the efficient and lightweight framework HAI-LLM, using 16-way zero-bubble pipeline parallel, 8-way expert parallel, and ZeRO-1 data parallel. Given that DeepSeek-V2 has fewer activation parameters and recalculates some operators to save activation memory, it can be trained without tensor parallel, thus reducing communication overhead.
In addition, to further improve training efficiency, the research overlaps computation and communication, and customizes faster CUDA kernels for communication between experts, routing algorithms, and linear fusion calculations.
Experiment results
The research evaluated DeepSeek-V2 on a variety of English and Chinese benchmarks and compared it with representative open-source models. The evaluation results show that, even with only 21B activation parameters, DeepSeek-V2 still achieved top performance among open-source models, becoming the strongest open-source MoE language model.
It’s noteworthy that compared to the basic version, DeepSeek-V2 Chat (SFT) showed significant improvements in GSM8K, MATH, and HumanEval evaluations. Moreover, DeepSeek-V2 Chat (RL) further improved the performance of mathematics and code benchmark tests.
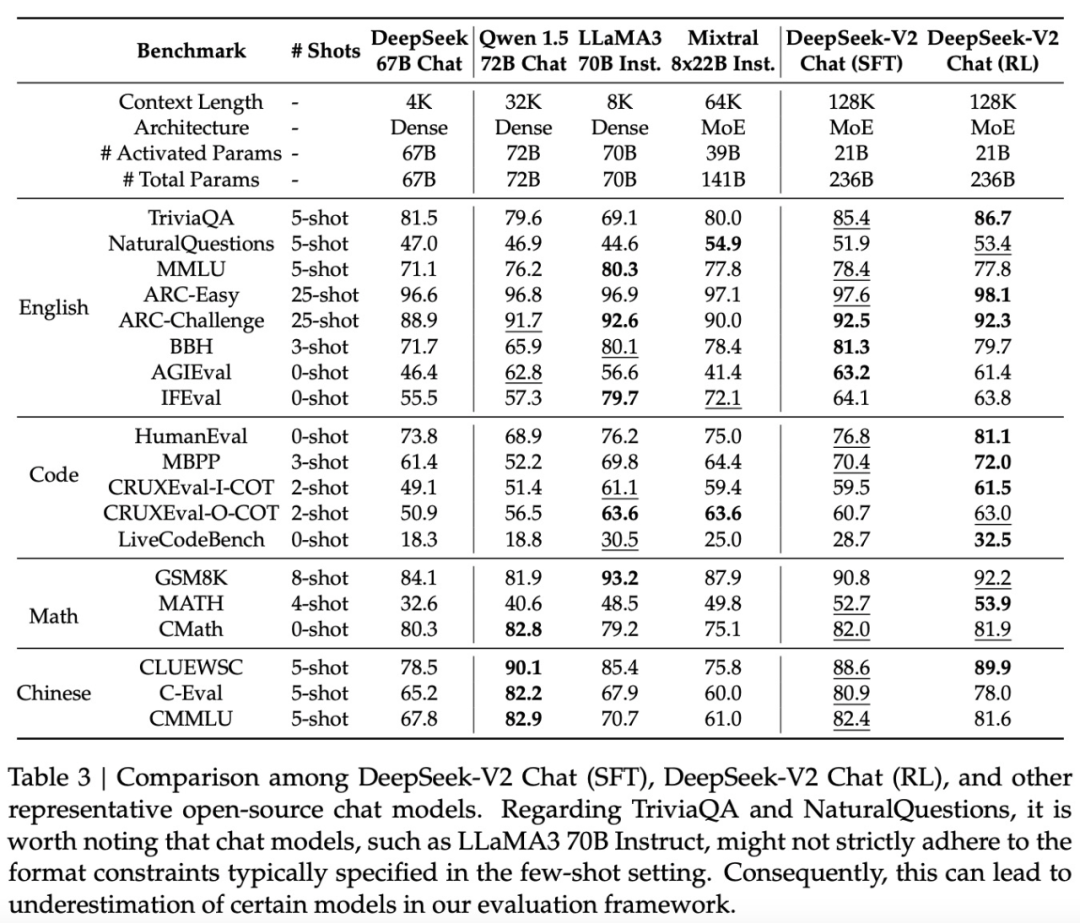
Open-ended generation evaluations. The research team continues to conduct additional evaluations of the model on open-ended dialogue benchmarks. For English open-ended dialogue generation, they use MT-Bench and AlpacaEval 2.0 as benchmarks. The evaluation results in Table 4 indicate that DEEPSEEK-V2 Chat (RL) has significant performance advantages compared to DEEPSEEK-V2 Chat (SFT). This result demonstrates the effectiveness of reinforcement learning training in improving consistency.
Compared with other open-source models, DEEPSEEK-V2 Chat (RL) outperforms both Mistral 8x22B Instruct and Qwen1.5 72B Chat in tests on both benchmarks.
Compare to LLaMA3 70B Instruct, DEEPSEEK-V2 Chat (RL) shows competitive performance on MT-Bench and significantly outperforms on AlpacaEval 2.0.
These results highlight the powerful performance of DEEPSEEK-V2 Chat (RL) in generating high-quality and contextually relevant responses, especially in instruction-based dialogue tasks.
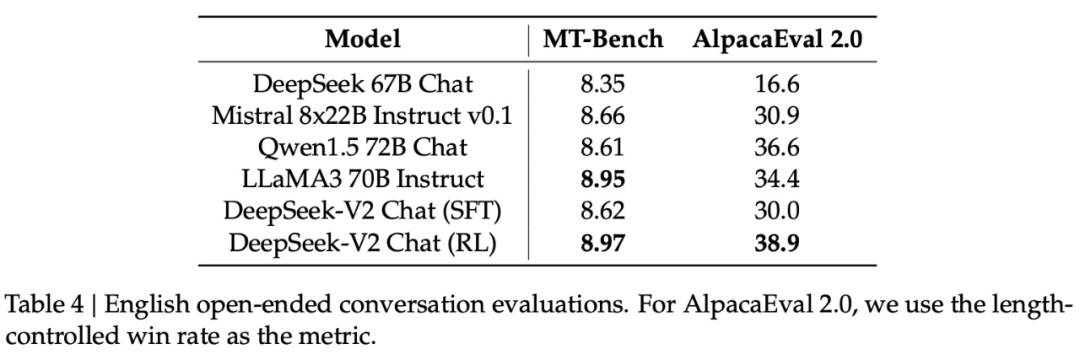
The research team evaluated the open-ended generation capabilities of the Chinese large model community based on AlignBench. As shown in Table 5, DEEPSEEK-V2 Chat (RL) has a slight advantage over DEEPSEEK-V2 Chat (SFT). Particularly noteworthy is that DEEPSEEK-V2 Chat (SFT) greatly surpasses all open-source Chinese models, with it being significantly better in Chinese reasoning and language than the second best open source model, Qwen1.5 72B Chat.
In addition, both DEEPSEEK-V2 Chat (SFT) and DEEPSEEK-V2 Chat (RL) outperform GPT-4-0613 and ERNIEBot 4.0, consolidating their own models’ top LLM position in supporting Chinese. Specifically, DEEPSEEK-V2 Chat (RL) performs exceptionally well in Chinese comprehension, outperforming all other models, including GPT-4-Turbo-1106-Preview. However, DEEPSEEK-V2 Chat (RL)’s reasoning capability still lags behind giant models such as Erniebot-4.0 and GPT-4.
Related posts
