ECCV 2024 | If you want to improve the performance of GPT-4V and Gemini detection tasks, you need this kind of hint model
Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various tasks. However, their potential in detection tasks remains underestimated. In complex object detection tasks requiring precise coordinates, MLLMs often miss target objects or provide inaccurate bounding boxes due to hallucinations. To empower MLLMs in detection tasks, existing work necessitates collecting large, high-quality instruction datasets and fine-tuning open-source models. This process is time-consuming and cannot leverage the more powerful visual understanding capabilities of closed-source models.
To address these challenges, Zhejiang University, in collaboration with the Shanghai Artificial Intelligence Laboratory and the University of Oxford, proposed DetToolChain, a new prompting paradigm to unleash the detection capabilities of MLLMs without requiring training. This research has been accepted by ECCV 2024.
To address MLLM’s issues in detection tasks, DetToolChain focuses on three points:
- Designing visual prompts for detection, which are more direct and effective than traditional textual prompts in conveying positional information to MLLMs.
- Breaking down complex detection tasks into smaller, simpler tasks.
- Using a chain-of-thought approach to gradually refine detection results, minimizing hallucinations in MLLMs.
Based on these insights, DetToolChain includes two key designs:
- A comprehensive set of visual processing prompts that are directly drawn on images to significantly bridge the gap between visual and textual information.
- A comprehensive set of detection reasoning prompts to enhance spatial understanding of detection targets and gradually determine the final precise location using a sample-adaptive detection toolchain.
By integrating DetToolChain with MLLMs like GPT-4V and Gemini, various detection tasks can be supported without instruction fine-tuning, including open vocabulary detection, descriptive target detection, referential expression understanding, and directional target detection.

Paper Title: DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
Paper Link: https://arxiv.org/abs/2403.12488
What is DetToolChain?
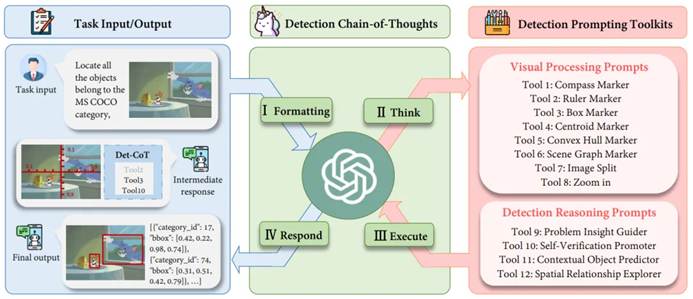
Figure 1: The overall framework of DetToolChain
As shown in Figure 1, for a given query image, MLLM is instructed to perform the following steps:
I. Formatting: Convert the raw input format of the task into an appropriate instruction template as input for MLLM. II. Think: Decompose specific complex detection tasks into simpler sub-tasks and select effective prompts from the detection prompt toolkit. III. Execute: Iteratively execute specific prompts in sequence. IV. Respond: Utilize MLLM’s reasoning ability to supervise the entire detection process and return the final response.
Detection Prompt Toolkit: Visual Processing Prompts
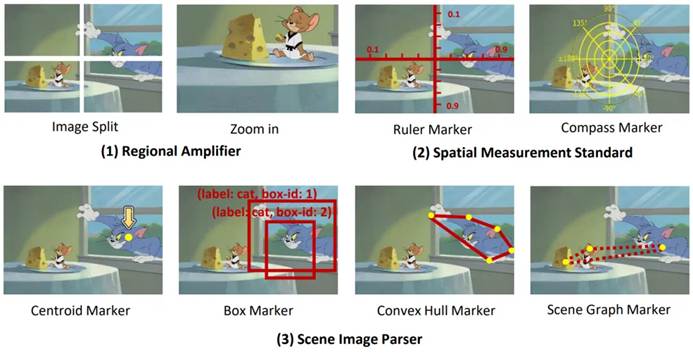
Figure 2: Illustration of visual processing prompts.
We designed (1) Regional Amplifier, (2) Spatial Measurement Standard, and (3) Scene Image Parser to enhance MLLMs’ detection capabilities from different perspectives.
As shown in Figure 2:
- Regional Amplifier aims to enhance the visibility of regions of interest (ROI) in MLLMs, including cropping the original image into different sub-regions focusing on the target objects. Additionally, the amplification function allows for fine-grained observation of specific sub-regions within the image.
- Spatial Measurement Standard provides clearer references for target detection by overlaying rulers and compasses with linear scales on the original image, as shown in Figure 2 (2). These auxiliary rulers and compasses enable MLLMs to output accurate coordinates and angles using the translation and rotation references overlaid on the image. Essentially, this auxiliary line simplifies the detection task, allowing MLLMs to read the coordinates of objects rather than directly predicting them.
- Scene Image Parser marks predicted object locations or relationships, utilizing spatial and contextual information to understand spatial relationships within the image. The Scene Image Parser can be divided into two categories: First, for individual target objects, we mark the predicted objects with centroids, convex hulls, and bounding boxes with labeled names and box indexes. These markers represent object location information in different formats, enabling MLLMs to detect diverse objects of different shapes and backgrounds, especially irregularly shaped or heavily occluded objects. For example, the convex hull marker marks the boundary points of an object and connects them into a convex hull, enhancing the detection performance of very irregularly shaped objects. Second, for multiple targets, we connect the centers of different objects using a scene graph marker to highlight the relationships between objects in the image. Based on the scene graph, MLLMs can use contextual reasoning capabilities to optimize predicted bounding boxes and avoid hallucinations. For example, as shown in Figure 2 (3), Jerry is supposed to eat cheese, so their bounding boxes should be very close.
Detection Prompt Toolkit: Detection Reasoning Prompts

To improve the reliability of predicted boxes, we implemented detection reasoning prompts (as shown in Table 1) to check the prediction results and diagnose potential issues. First, we proposed a Problem Insight Guider, highlighting difficult problems and providing effective detection suggestions and similar examples for the query image. For example, for Figure 3, the Problem Insight Guider defines the query as a small object detection problem and suggests solving it by amplifying the surfboard area. Second, to leverage MLLMs’ inherent spatial and contextual capabilities, we designed a Spatial Relationship Explorer and a Contextual Object Predictor to ensure detection results align with common sense. As shown in Figure 3, a surfboard may co-occur with the ocean (contextual knowledge), and there should be a surfboard near the surfer’s feet (spatial knowledge). Additionally, we applied a Self-Verification Promoter to enhance the consistency of multi-turn responses. To further enhance MLLMs’ reasoning capabilities, we adopted widely used prompting methods such as debating and self-debugging. For detailed descriptions, please refer to the original text.
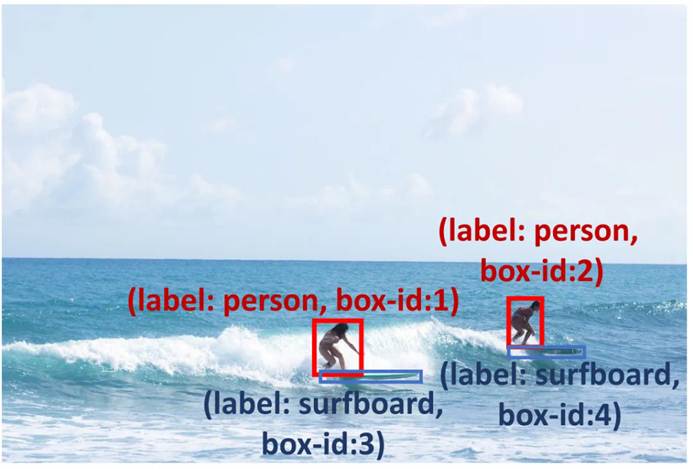
Figure 3: Detection reasoning prompts can help MLLMs solve small object detection problems, such as locating the surfboard under the surfer’s feet using common sense and encouraging the model to detect the surfboard in the ocean.

Figure 4: An example of DetToolChain applied to rotated object detection (HRSC2016 dataset)
Experiments: Surpassing Fine-Tuning Methods Without Training
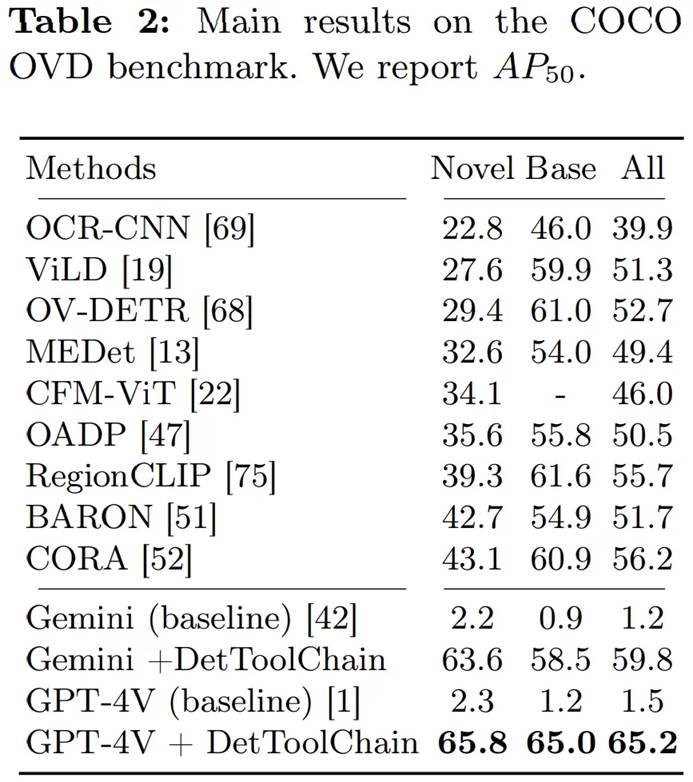
As shown in Table 2, we evaluated our method on open vocabulary detection (OVD), testing the AP50 results for 17 new classes, 48 base classes, and all classes in the COCO OVD benchmark. The results show that using our DetToolChain, the performance of GPT-4V and Gemini improved significantly.
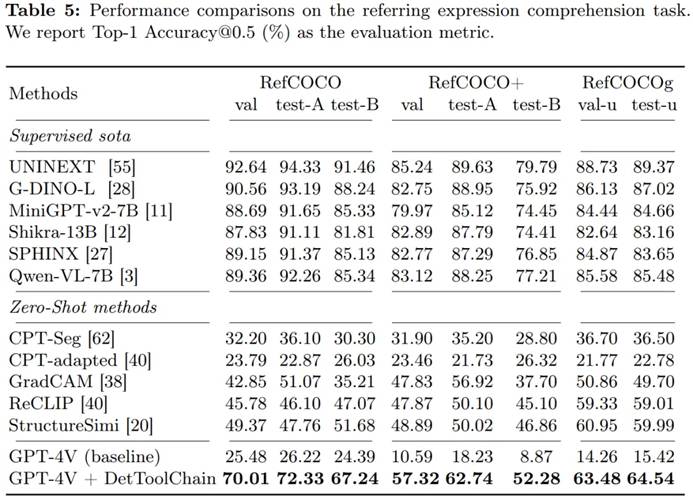
To demonstrate the effectiveness of our method in referential expression understanding, we compared our method with other zero-shot methods on the RefCOCO, RefCOCO+, and RefCOCOg datasets (Table 5). On RefCOCO, DetToolChain improved the performance of the GPT-4V baseline by 44.53%, 46.11%, and 24.85% on val, test-A, and test-B, respectively, showcasing DetToolChain’s superior referential expression understanding and localization performance under zero-shot conditions.
Related posts
