Is Sora a world simulator? The world’s first comprehensive review analyzes the universal world model.
In the field of video generation, Sora, released by OpenAI, has attracted wide attention due to its strong simulation ability, showing a preliminary understanding of the physical world. Leading video generation company Runway stated in its technical blog that the next-generation product of the Gen-2 life-video system will be realized through the general world model. In the field of autonomous driving, both Tesla and Wayve have stated that they are building their end-to-end autonomous driving systems using the future prediction features of the world model. In the broader field of general robot intelligence, LeCun has repeatedly expressed great interest in the potential of world models in his speeches, predicting that world models will replace autoregressive models as the basis for next-generation intelligent systems.
To comprehensively explore and summarize the latest progress of the world model, researchers from Beijing Excellent Vision Technology Co., Ltd. (Excellent Technology) jointly launched the world’s first comprehensive review of the general world model with several domestic and foreign institutions (Institute of Automation, Chinese Academy of Sciences, National University of Singapore, Institute of Computing Technology, Chinese Academy of Sciences, Shanghai Artificial Intelligence Laboratory, Mychi, Northwestern Polytechnical University, Tsinghua University, etc.).
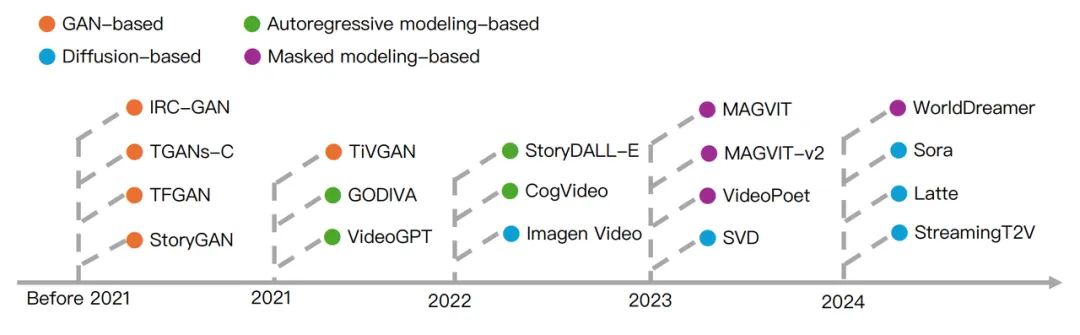
This review, based on more than 260 documents, provides a detailed analysis and discussion of world model research and applications in fields such as video generation, autonomous driving, intelligent entities, and general robots. In addition, the review also looks at the current challenges and limitations of world models and looks forward to their future development.
Researchers from Excellent Technology said they would continue to update more research progress on the general world model in the GitHub project, hoping that the review could serve as a research reference for the general world model.

-
Paper link: https://arxiv.org/abs/2405.03520 -
GitHub project link: https://github.com/GigaAI-research/General-World-Models-Survey
Firstly, a video generation world model refers to the use of world model technology to generate and edit videos, so as to understand and simulate real-world scenarios. This way, complex visual information can be better understood and expressed, providing new possibilities for artistic creation.
Secondly, an autonomous driving world model refers to the use of video generation and prediction technology to create and understand driving scenarios, and to learn driving behaviors and strategies from these scenarios, which is important for implementing end-to-end autonomous driving systems.
Lastly, an intelligent entity world model refers to the use of video generation and prediction technology to establish interactions between intelligent entities and the environment in dynamic environments. Different from the autonomous driving model, the intelligent entity world model builds an intelligent strategy network suitable for various environments and situations; these intelligent entities may be virtual, such as controlling character behavior in games, or they may be physical, such as controlling robots to perform tasks in the physical world. In this way, intelligent entity world models provide new solutions for intelligent interaction and intelligent control.
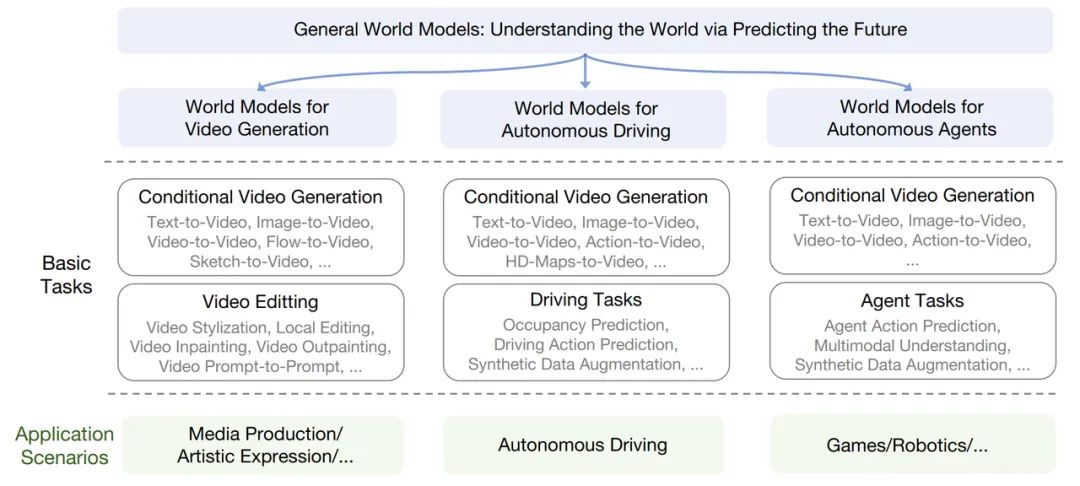
Field of Video Generation
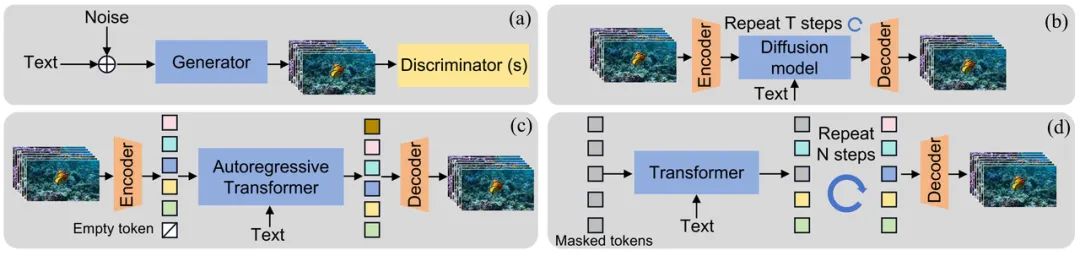
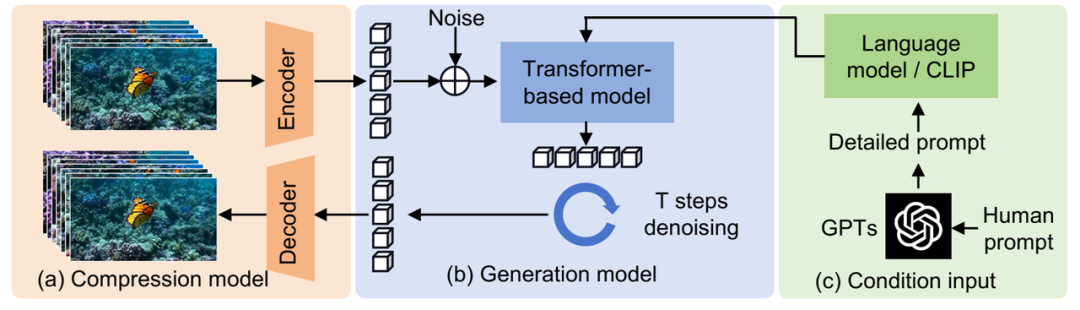
- Compression model: This model compresses the original video in time and space, converts it into hidden space features for representation, and has a decoder that can map hidden space features back to the original video.
- Transformer-based Diffusion Model: Similar to DiT (Scalable Diffusion Models with Transformers) method, this model continuously reduces the noise of visual features in the latent space.
- Language model: The large language model is used to encode the user’s inputs into detailed promts to control the generation of the video.
Autonomous driving field
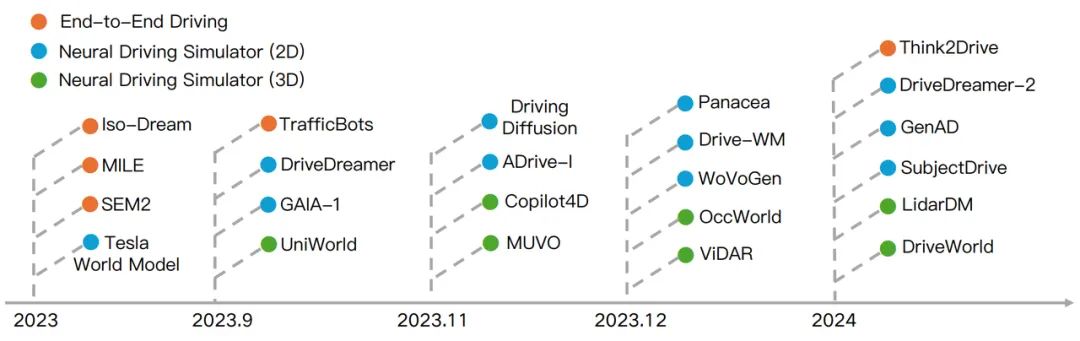
The above methods were experimented on CARLA v1, but face the challenge of data inefficiency in CARLA v2. To deal with the complexity of CARLA v2 scenes, Think2Drive proposes a model-based reinforcement learning method for autonomous driving, which encourages the planner to “think” in the learned latent space. This method significantly improves training efficiency by utilizing low-dimensional state space and parallel computing tensors.
High-quality data is the cornerstone of training deep learning models. Although internet text and image data are low-cost and easy to acquire, there are many challenges in acquiring data in the field of autonomous driving, including the complexity of sensors and privacy issues, especially when acquiring long-tail targets that directly affect actual driving safety. World models are crucial for understanding and simulating the complex physical world.
Some recent research has introduced diffusion models into the field of autonomous driving to construct world models as neural simulators, generating the necessary autonomous 2D driving videos. In addition, some methods use world models to generate 3D occupancy grids or LiDAR point clouds of future scenes.
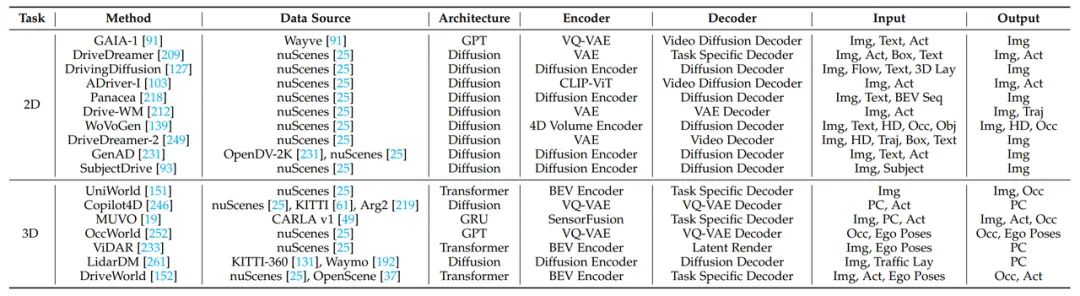
The table below provides a summary of the driving scene data generation methods based on world models.
Intelligent agent and robotics field
Therefore, a central topic in this field is how intelligent agents can learn to plan in unknown and complex environments. One way to solve this problem is to allow the intelligent agent to accumulate experience from interactions with the environment, and learn behavior directly from the experience without modeling the state changes of the environment (i.e., model-free reinforcement learning). Although this solution is simple and flexible, the learning process depends on many interactions with the environment, which is very costly.
World Models is the first research to introduce the concept of world models in the field of reinforcement learning. It models the knowledge of the world from the agent’s experience and gains the ability to predict the future. This work suggests that even a simple recurrent neural network model can capture the dynamic information of the environment and support the agent in learning and evolving strategies in the model. This learning paradigm is called “learning in the imagination”. With a world model, the cost of experiments and failures can be significantly reduced.
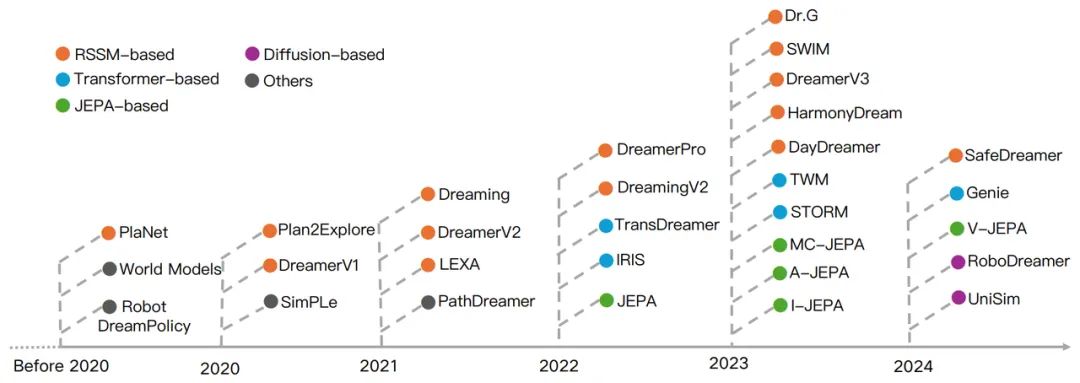
The diagram below provides an overview of the development of world models in the field of intelligent agents and robotics, with different colors indicating different structures of world models. Where the RSSM (PlatNet, DreamerV1, DreamerV2, DreamerV3, etc.) dominates, while the Transformer (TransDreamer, IRIS, Genie, etc.), JEPA (JEPA, MC-JEPA, A-JEPA, V-JEPA, etc.) and diffusion models (RoboDreamer, UniSim) have received increasing attention since 2022.
Joint-Embedding Predictive Architecture (JEPA) was proposed by LeCun et al., and learns the mapping relationship from input data to predicted output. Unlike traditional generative models, it doesn’t directly generate pixel-level outputs; instead, it predicts in a higher-level representation space, allowing the model to focus on learning more semantic features. Another core idea of JEPA is to train the network through self-supervised learning so that it can predict missing or hidden parts in the input data. Through self-supervised learning, the model can pretrain on a large amount of unlabeled data, then fine-tune on downstream tasks, thus improving its performance on various visual and general tasks.
The Transformer originates from natural language processing tasks. Based on the principle of attention mechanism, it allows the model to pay attention to different parts of the input data at the same time. In many domains that require long-term dependencies and memory-based reasoning, the Transformer has been proven to be more effective than recurrent neural networks, and therefore has received increasing attention in the field of reinforcement learning in recent years. Since 2022, there have been several pieces of work attempting to build world models based on Transformer and its variants, achieving better performance on some complex memory interaction tasks than RSSM. Among them, Google’s Genie drew considerable attention. This work builds a generative interactive environment based on ST-Transformer, trained through self-supervised learning on large amounts of unlabeled internet video data. Genie demonstrates a new paradigm of customizable manipulative world models, offering massive potential for the future development of world models.
Lately, some methods have worked on building an intelligent agent world model based on diffusion models, with RoboDreamer learning constitutive world models to enhance the robot’s imagination. It decomposes the video generation process and utilizes the inherent combinability of natural language. In this way, it can synthesize videos of unseen combinations of objects and actions. RoboDreamer decomposes language instructions into a set of basic elements, then used as different conditions for a set of model-generated videos. This approach not only demonstrated powerful zero-sample generalization capabilities but also achieved impressive results in multimodal instruction video generation and robot operation task deployment. UniSim is a generative simulator for real-world physical interactions. UniSim includes a unified generative framework that takes action as input and integrates various datasets. Through this approach, UniSim can simulate the visual results of high-level instructions and low-level control, allowing for the creation of controllable game content and training embodied intelligent objects in a simulated environment.
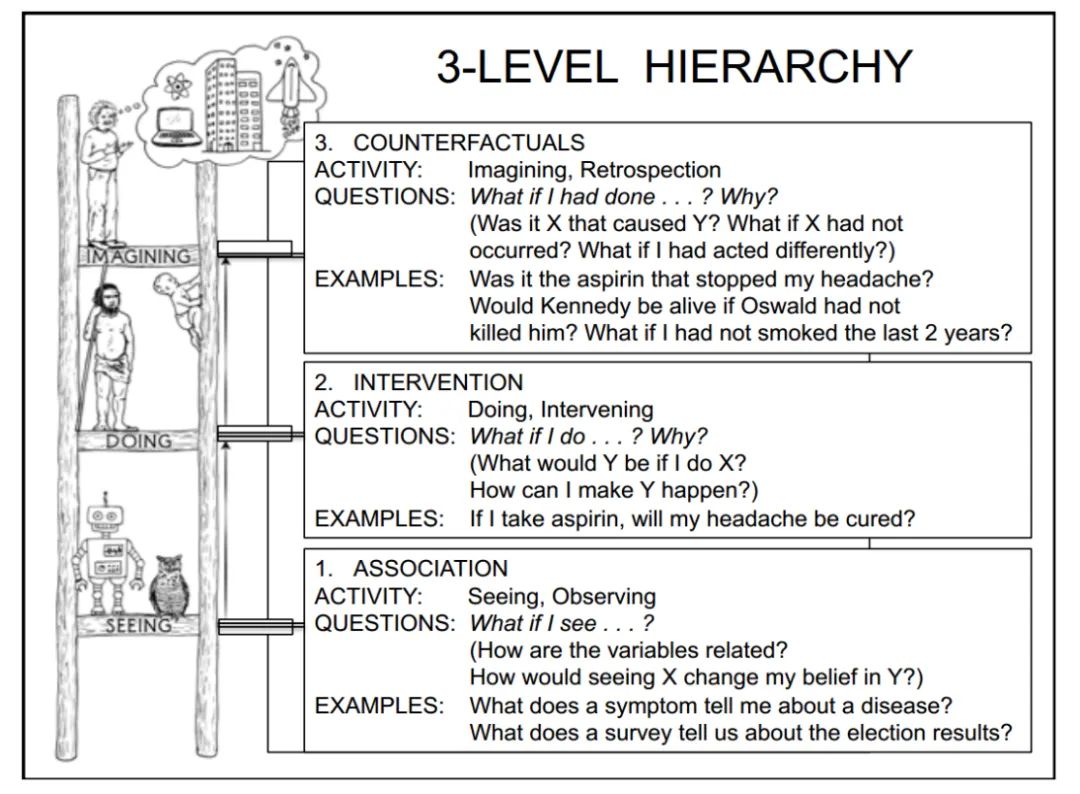
For instance, imagine an autonomous vehicle faced with a sudden traffic accident or a robot in a new environment. A world model with counterfactual reasoning capabilities can simulate the different actions they might take, predict outcomes, and choose the safest response. This would significantly improve the decision-making abilities of autonomous intelligent systems, helping them handle new and complex scenarios.
Related posts
